MySQL索引详解
MySQL索引篇
索引介绍
索引是什么
官方介绍索引是帮助MySQL高效获取数据的数据结构。更通俗的说,数据库索引好比是一本书前面的目
录,能加快数据库的查询速度。
索引的优势和劣势
优势:
可以提高数据检索的效率,降低数据库的IO成本,类似于书的目录。 – 检索
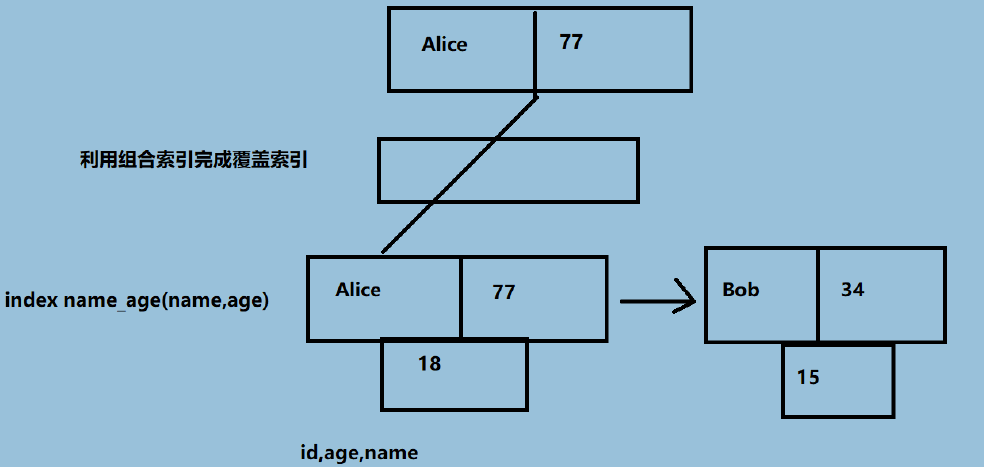
通过索引列对数据进行排序,降低数据排序的成本,降低了CPU的消耗。 –排序- 被索引的列会自动进行排序,包括【单列索引】和【组合索引】,只是组合索引的排序要复杂一些
- 如果按照索引列的顺序进行排序,对应order by语句来说,效率就会提高很多
- where 索引列 在存储引擎层 处理 索引下推 ICP
- 覆盖索引 select 字段 字段是索引
劣势:
索引会占据磁盘空间
索引虽然会提高查询效率,但是会降低更新表的效率**。比如每次对表进行增删改操作,
MySQL不仅要保存数据,还有保存或者更新对应的索引文件。
索引的分类
- 单列索引
- 组合索引
- 全文索引
- 空间索引
- 位图索引 Oracle
索引的使用
创建索引
单列索引之普通索引
1
2CREATE INDEX index_name ON table(column(length)) ;
ALTER TABLE table_name ADD INDEX index_name (column(length)) ;单列索引之唯一索引
1
2CREATE UNIQUE INDEX index_name ON table(column(length)) ;
alter table table_name add unique index index_name(column);单列索引之全文索引
1
2CREATE FULLTEXT INDEX index_name ON table(column(length)) ;
alter table table_name add fulltext index_name(column)组合索引
1
ALTER TABLE article ADD INDEX index_titme_time (title(50),time(10)) ;
删除索引
1 | DROP INDEX index_name ON table |
查看索引
1 | SHOW INDEX FROM table_name \G |
索引原理分析
索引的存储结构
索引存储结构
索引是在存储引擎中实现的,也就是说不同的存储引擎,会使用不同的索引
MyISAM和InnoDB存储引擎:只支持B+ TREE索引, 也就是说默认使用BTREE,不能够更换
MEMORY/HEAP存储引擎:支持HASH和BTREE索引
B树和B+树
数据结构示例网站
https://www.cs.usfca.edu/~galles/visualization/Algorithms.html
B树图示
B树是为了磁盘或其它存储设备而设计的一种多叉(下面你会看到,相对于二叉,B树每个内结点有多个
分支,即多叉)平衡查找树。 多叉平衡
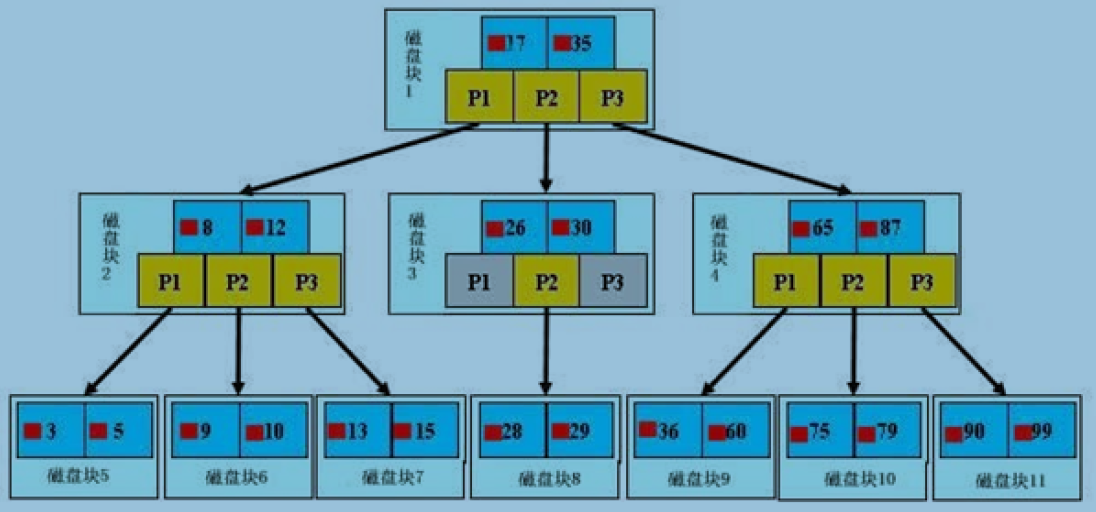
- B树的高度一般都是在2-4这个高度,树的高度直接影响IO读写的次数。
- 如果是三层树结构—支撑的数据可以达到20G,如果是四层树结构—支撑的数据可以达到几十T
B和B+的区别
B树和B+树的最大区别在于非叶子节点是否存储数据的问题。
B树是非叶子节点和叶子节点都会存储数据。
B+树只有叶子节点才会存储数据,而且存储的数据都是在一行上,而且这些数据都是有指针指向
的,也就是有顺序的。
非聚集索引(MyISAM)
主键索引
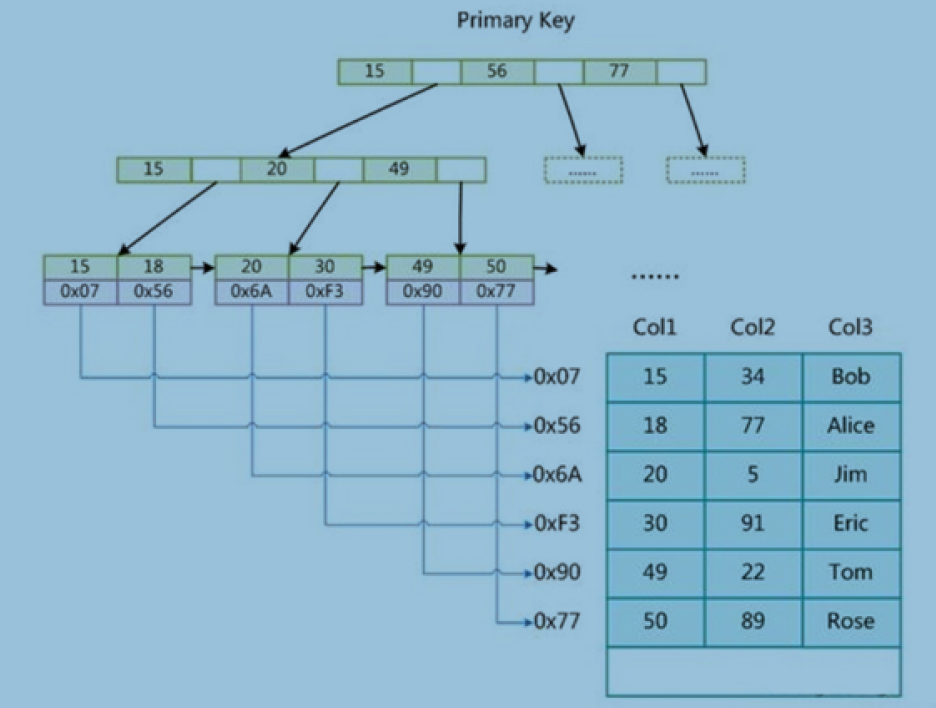
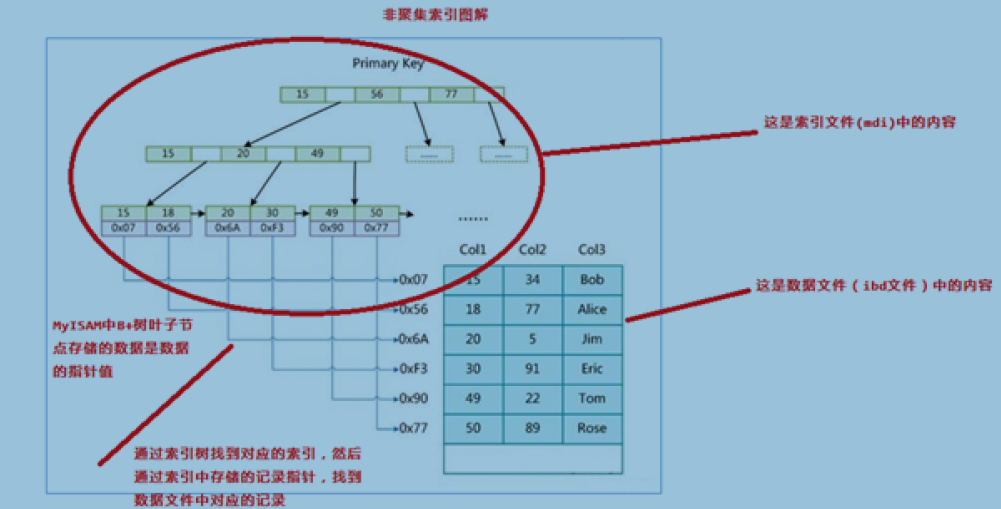
辅助索引(次要索引)
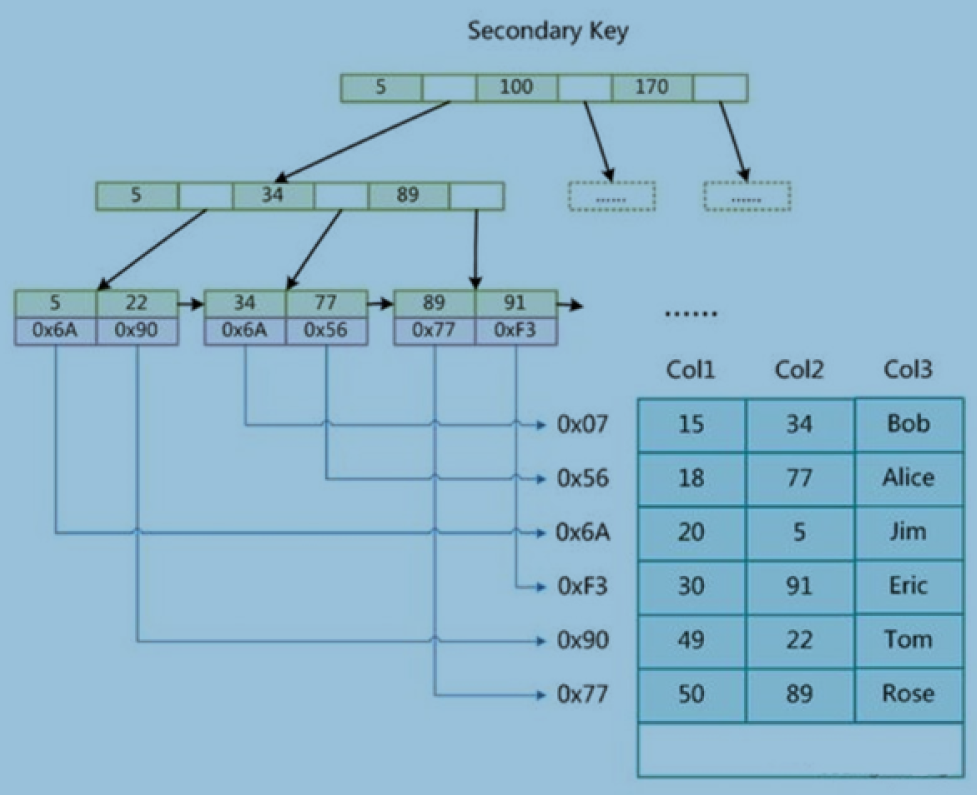
聚集索引(InnoDB)
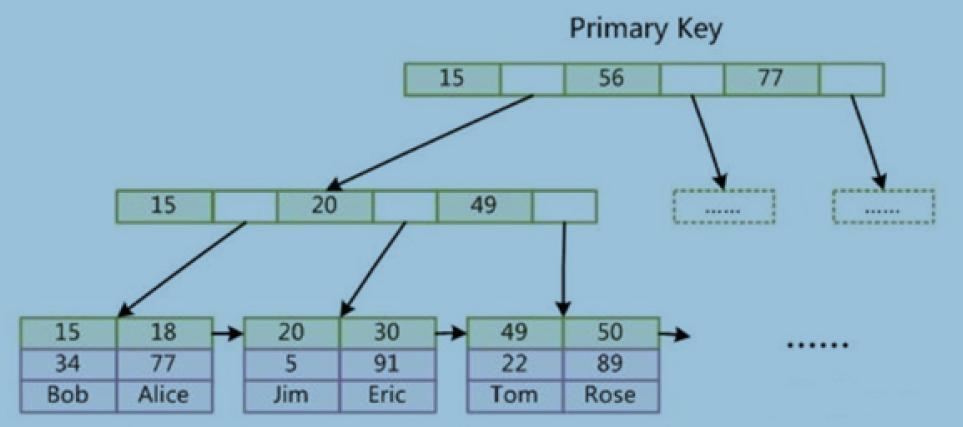
主键索引
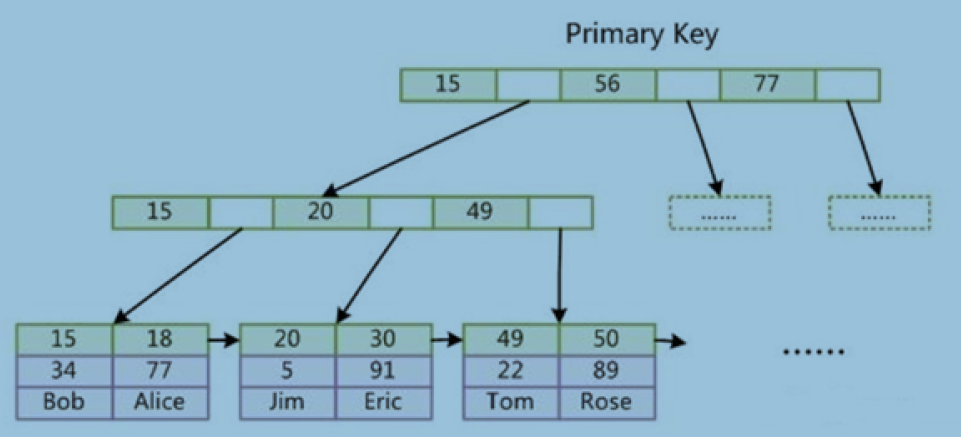
主键:
- 建主键
- 没建主键
找唯一字段 当主键
自动生成伪列 当主键
主键创建
自增整数
不要用大字符串比如 uuid —- 》 雪花算法 snowflakes
辅助索引(次要索引)
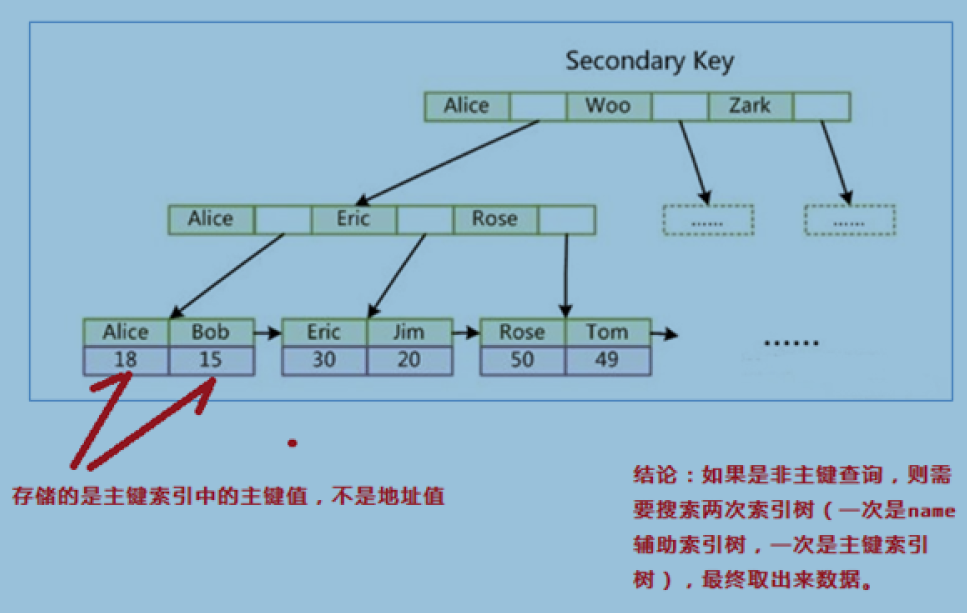
select * from t where id=15
select * from t where name=’Alice’
回表(从辅助索引树上找到主键后在主键索引树下找到数据)
select name from t where name=’Alice’ 给name做了索引
select id,name from t where name=’Alice’ 覆盖索引
select * from t where name=’Alice’ 只找一棵索引树 ?
形成索引树
利用组合索引 完成覆盖索引(利用组合索引完成在辅助索引树的遍历,不回表)